【环球网科技综合报道】近日, 在第二届视觉对话竞赛Visual Dialogue Challenge中,阿里AI击败了微软、首尔大学等十支参赛队伍,获得冠军。
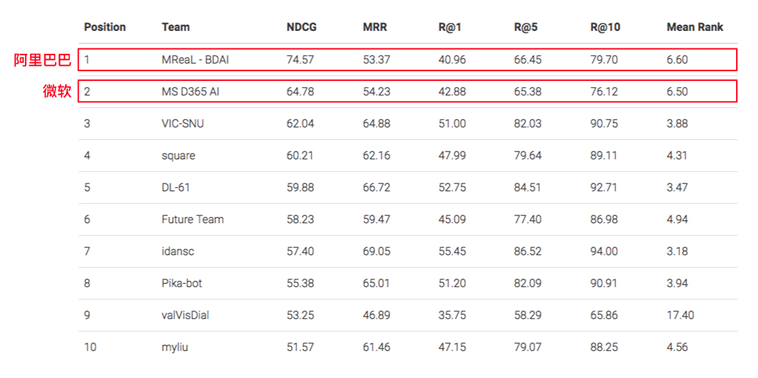
(阿里AI在视觉对话竞赛中得冠)
据了解,视觉对话竞赛由美国佐治亚理工大学、Facebook人工智能实验室(FAIR)等机构联合全球视觉技术领域顶级学术会议CVPR发起,是目前视觉对话领域最权威的竞赛之一。
该竞赛要求参赛的AI在看完近万张图片后,回答出人类对于任一图片任一内容的提问。竞赛结果显示,阿里AI以74.57%的准确率获得冠军,将上一届比赛的纪录提高了16.82%。在相同的数据集中,人类的准确率仅为64.27%。
传统的视觉AI主要针对目标的检测和识别,例如识别出图片是否是一只猫,但对复杂场景中目标之间的逻辑关系理解、推理能力较弱,无法回答“这只猫旁边的男生穿了什么颜色的衣服”等复杂问题,也难以将图片信息转化为人类理解的语言输出。
阿里AI的突破在于提出了“递归探索对话模型”,综合集成了图像识别、关系推理与自然语言理解三大能力,它通过高效利用标注信息学习出模仿人类认知复杂场景的思维方式,能够有效识别图片里的实体以及它们之间的关系,推理出图片所描述的事件内容,并通过对上下文进行有效建模,理解人类提出的问题及真实意图,给出自然准确的回复。

(视觉对话中,AI可以从容应对人类提问,左为AI,右为人类)
视觉对话是近年来快速崛起的AI研究方向,目的在于教会机器用自然语言与人类讨论视觉内容。如果说视觉识别技术,让机器具备了视觉能力;那么视觉对话技术,则使得机器拥有了对真实视觉世界的理解与推断能力,意味着AI的认知能力将迈上新的台阶。
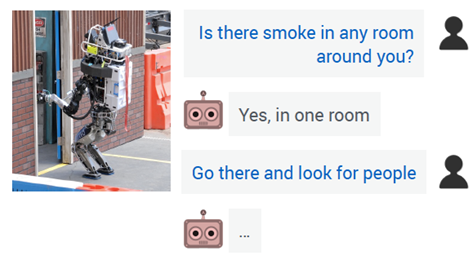
(视觉对话技术有望人类提高地震救援效率)
据了解,这项技术未来将被应用在人机交互诸多场景:地震后在废墟中寻找幸存者的救援机器人,能够更加及时、高效地综合指挥指令和场景信息作出行动;视障人士可以通过提问阿里AI,理解网络照片中的内容,了解自身所处的周围环境;无人驾驶车辆对影响因子的意图理解会更为准确,乘客的乘坐体验更好。
(审核编辑: 林静)